目次
ChatGPT Advanced Data Analysisでファイルアップロード機能が利用可能に
有料ユーザーの早期機能アクセスにより、Advanced Data Analysisが利用可能になっています。この機能を利用することで、ファイルをアップロードし、ファイルに対してGPTに指示を出すことが出来ます。
以下ではPDFと画像に対してテキスト抽出を試してみました。
ChatGPT Advanced Data Analysis の有効化の方法
PDFファイルに対して直接OCRを行うことは出来ない
- 画像ベースのPDF: OCRによりテキスト抽出を行うことは出来ないようです。
- 埋め込みテキスト: PythonでPDFの埋め込みテキストを読み込むコードを実行し、その結果を取得出来るようです。(未検証)
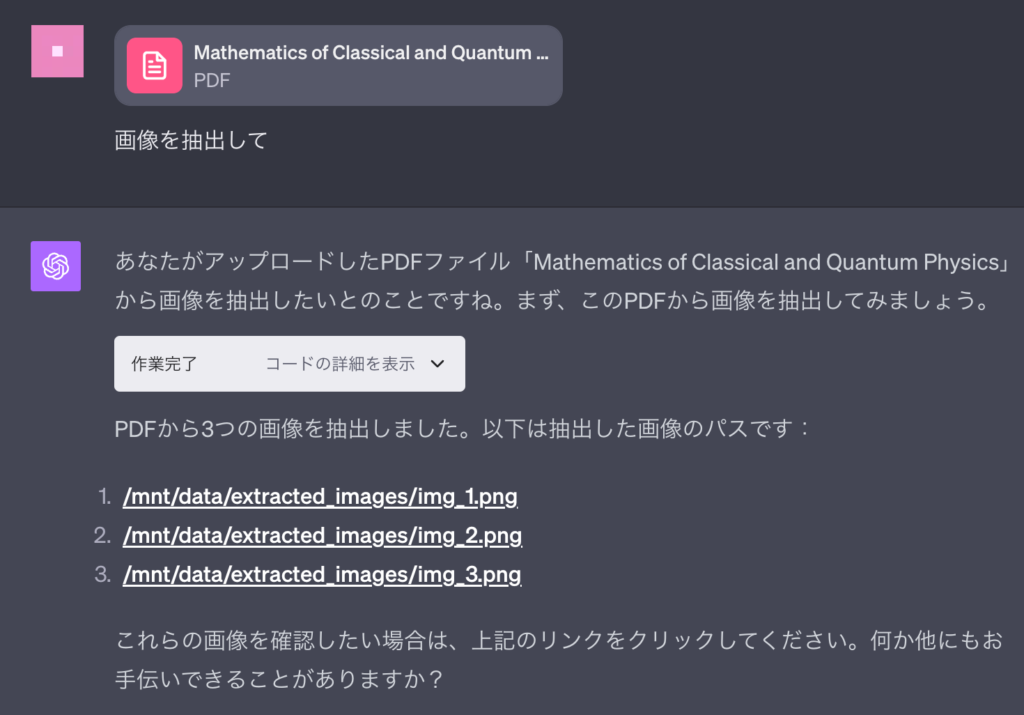
画像ベースPDFの抽出依頼
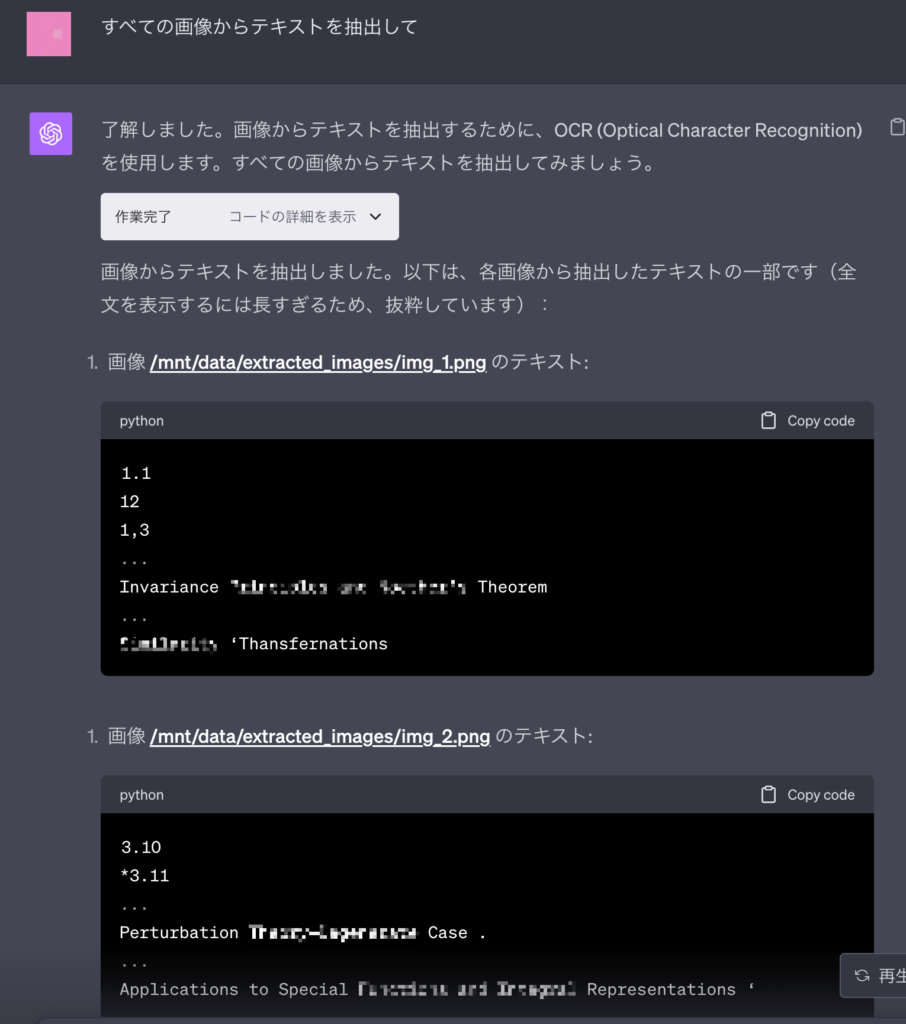
とはいっても、今回検証に利用したPDFは、画像ベースではありますが、テキストの埋め込みデータも持っているため、単純に画像ベースかテキストベースかといった以外の判断もあるのかもしれません。
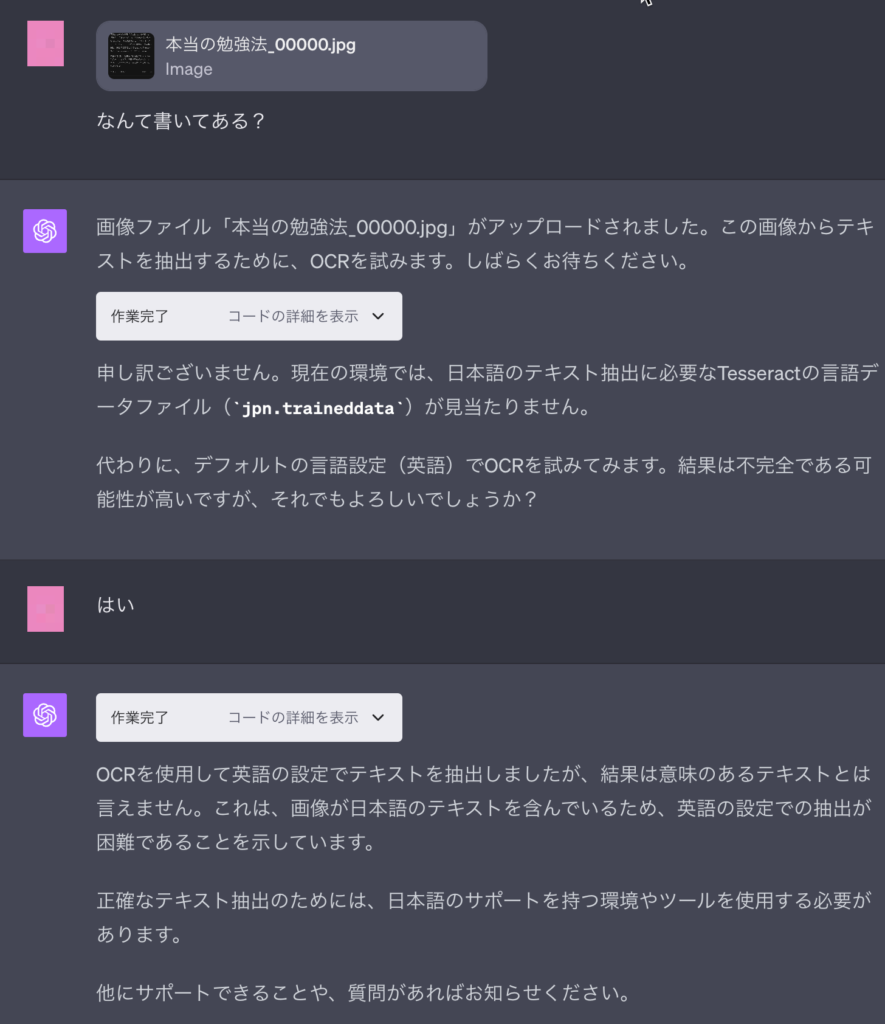
日本語の画像からはテキスト抽出不可
以下のように日本語で書かれた文章の画像に対してテキストの抽出を依頼しましたが、 日本語のテキスト抽出に必要なTesseractの言語データファイル(jpn.traineddata)が見当たらない ことが原因で抽出は行えませんでした。
日本語の画像からのテキスト抽出依頼
英語のPDFから画像抽出し、OCRを行う2段階の依頼でテキスト抽出可能
英語のテキスであれば、PDFから画像を抽出し、その結果からテキストを抽出することは可能なようです。ただし、テキストの位置は期待した結果とはなっていませんでした。
英語の画像ベースPDFからの画像抽出依頼
英語の画像からのテキスト抽出依頼